¿Qué es un estándar Open Data?
Las conexiones ODBC son utilizadas para comunicar internamente aplicaciones con bases de datos.
No son adecuadas de cara a ofrecer información al público en
general ya que requieren hacer pública información del servidor que aloja la
base de datos y son generalmente más complicadas de configurar.
Para la comunicación de información a través de internet se han creado las API.
Las API establecen estándares de comunicación mediante direcciones
URL que permiten recuperar información a través de peticiones HTTP GET a
servidores web.
Cada servidor web es libre de implementar su API de manera individual, pero para unificar la estructura y simplificar las comunicaciones se creó el estándar Open Data.
OData nace en 2007 de la mano de Microsoft y desde entonces se ha convertido en el principal estándar para la comunicación de información a través de la web.
Odata es utilizado por multitud de empresas para ofrecer la información de sus bases de datos a sus usuarios.
Algunos ejemplos notables son SAP, Facebook o Google.
Es posible acceder a datos mediante OData desde nuestro navegador. La página web del proyecto OData tiene varias fuentes públicas para realizar pruebas y aprender a utilizar el servicio.
Simplemente accediendo a los enlaces proporcionados podemos ver los ejemplos.
Utilizando el enlace a uno de los servicios podemos acceder a una respuesta OData y ver las partes que la componen.
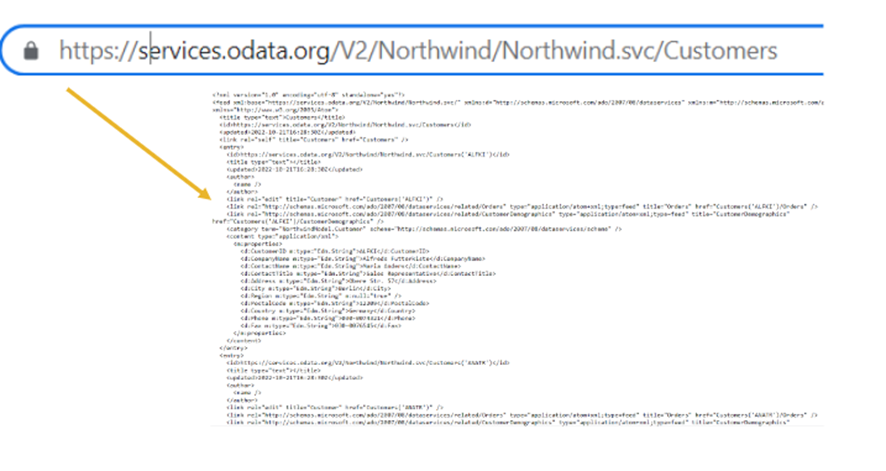
La primera parte es un encabezado con la información de la versión del estándar y el origen de la respuesta.
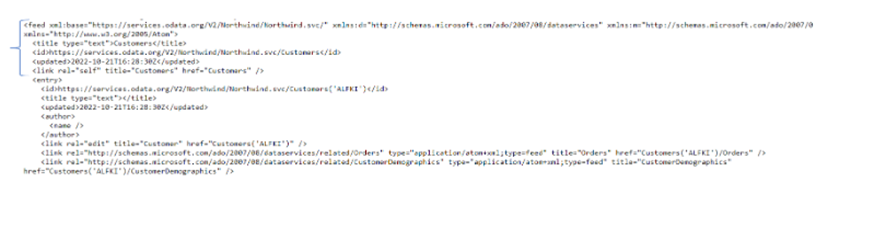
La segunda parte contiene información acerca de las columnas, los tipos de datos devueltos por la consulta y sus valores.
Esto se encuentra contenido entre las etiquetas <entry>.
Cada fila de la tabla devuelta tendrá una etiqueta entry distinta.
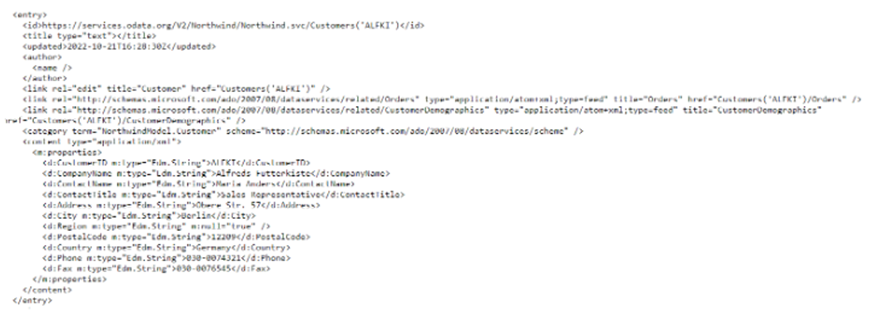
Explicación de la estructura de queries de OData
Mediante OData no solo es posible extraer la tabla de datos completa, sino que además contiene un potente sistema de consulta que permite segmentar la información.
Estas queries permiten navegar por los diferentes recursos y
segmentar, ordenar o filtrar la información devuelta.
La documentación completa acerca de la construcción de una query está disponible en la página web del proyecto y resulta una guía muy útil para su uso.
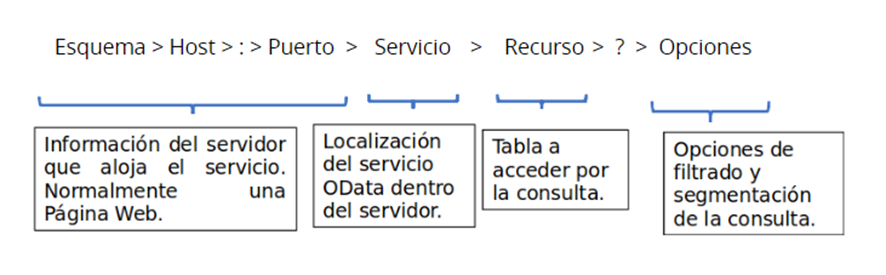
Una query se divide en las siguientes partes:
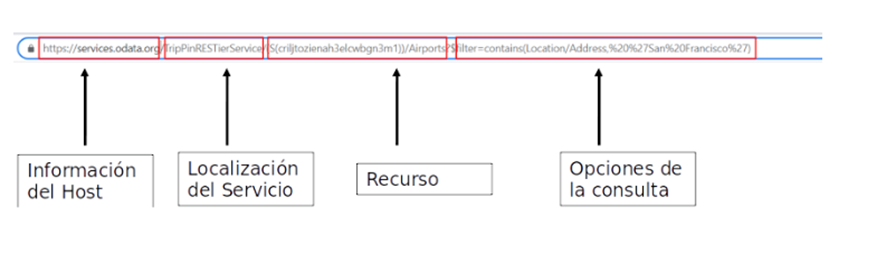
Las consultas tienen los siguientes caracteres reservados:
· Barra inclinada (/): Indica la localización de los recursos dentro de las carpetas.
· Interrogante (?): Indica el comienzo de las opciones de la consulta.
· Símbolo de dólar ($): Indica que la palabra a continuación es una opción de la consulta.
· Comillas (""): Indica que los caracteres entre ellas son un texto literal.
· Simbolo et (&): Permite combinar opciones de filtro en una query.
La primera opción en las consultas es la navegación de recursos.
Si accedemos al servicio de ejemplo Northwind encontramos los distintos recursos que contiene bajo la etiqueta collections.
https://services.odata.org/V2/Northwind/Northwind.svc/

Si añadimos a la URL la dirección de un recurso nos devolverá su contenido. Por ejemplo, Customers.
https://services.odata.org/V2/Northwind/Northwind.svc/Customers
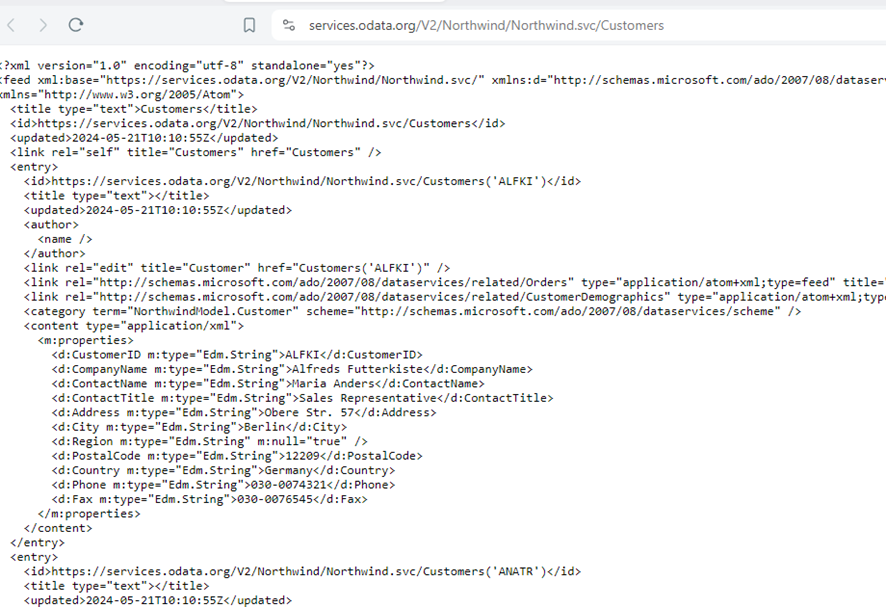
Una vez llegamos a una tabla podemos filtrarla.
La API de Northwind usa la versión ODATA V2.
Que permite los siguientes filtros:
· Comparadores lógicos (igual, mayor, menor, etc)
· Operadores lógicos (Y, o, no)
· Operaciones aritméticas (suma, resta, etc)
En la tabla se pueden ver sus palabras clave.
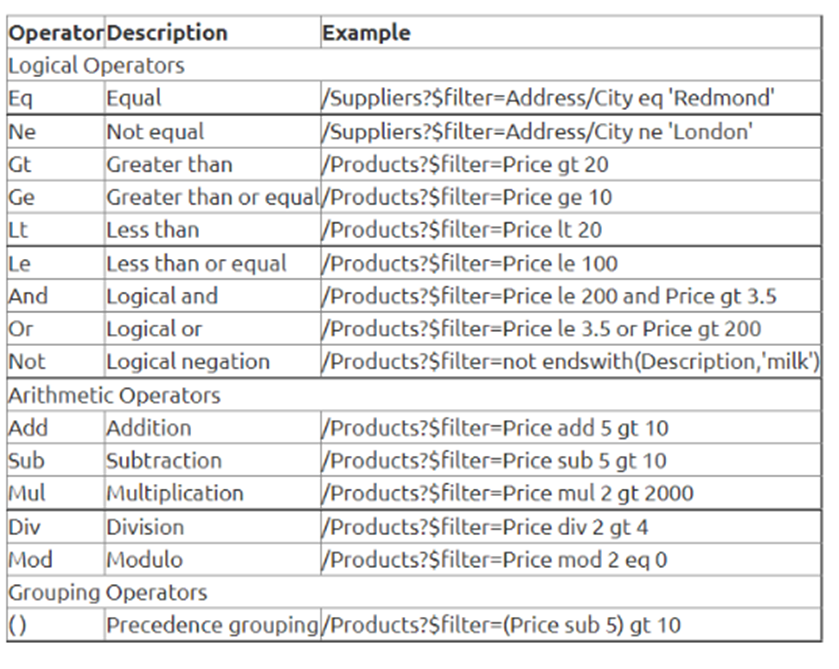
La estructura de un filtro se compone de 3 partes:
1. Llamada al
filtro y nombre de columna: Se puede extraer el nombre de la columna de los
campos entre las etiquetas <m: properties>. Estos campos tienen el
formato <d:<nombre de columna>>.
2. Palabras clave: Corresponde
a la columna Operator de la tabla anterior.
3. Valor de columna: Valor por el que se quiere filtrar la columna, debe ser del mismo tipo que la columna.
$filter=<nombre de columna> <Palabra clave> <Valor de columna>
Ejemplo: $filter=Price gt 20
Además de filtrar columnas mediante condiciones simples, se pueden combinar filtros mediante operadores lógicos:
· and: Ambas condiciones deben cumplirse.
· or: Una de las dos debe cumplirse.
· not: no debe cumplirse la condición.
La combinación se hace dejando un espacio entre las condiciones y el operador y se puede emplear paréntesis para ordenar la preferencia.
$filter=<columna1> <Comparador 1> <Valor 1> <Operador> <columna2> <Comparador 2> <Valor 2>
Ejemplo: $filter=Price le 200 and Price gt 3.5
Se puede pedir al servicio que devuelva las filas ordenadas mediante la instrucción orderby junto con las palabras clave asc para ascendente y desc para descendente:
$orderby=<nombre de columna> <Palabra
clave>
Ejemplo: $orderby=Price asc
A pesar de esta posibilidad NO SE RECOMIENDA realizar ninguna ordenación al realizar consultas salvo absoluta necesidad ya que son instrucciones pesadas de calcular y por sí mismas no reportan ningún beneficio al modelo de datos final.
OData permite también realizar selección de filas mediante las ordenes $top y $skip:
· La orden $top devuelve las primeras x filas de la tabla.
· La orden $skip devuelve toda la tabla excepto las primeras x filas.
$<top/skip>=<Valor>
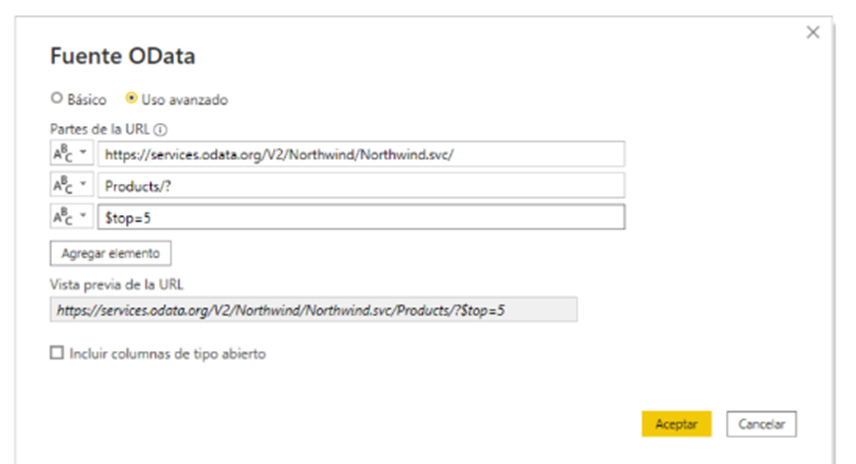
Ejemplo: $top=5
Todas estas opciones se pueden combinar usando el símbolo &:
$<Opcion 1>&$<Opcion 2>
Ejemplo: $filter=Price gt 20&$orderby=Price asc
La combinación de las opciones $orderby con $top o $skip es uno de los casos en los que es adecuado $orderby.
Existen muchas opciones adicionales que se pueden consultar en la documentación del proecto OData en www.odata.org. Es importante tener en cuenta lo siguiente:
· Cada versión tiene su propia documentación y versiones anteriores no implementan todas las opciones.
· Cada servicio es libre de hacer variaciones en la estructura básica. Es importante leer la documentación del servicio.
Conexión a un origen OData
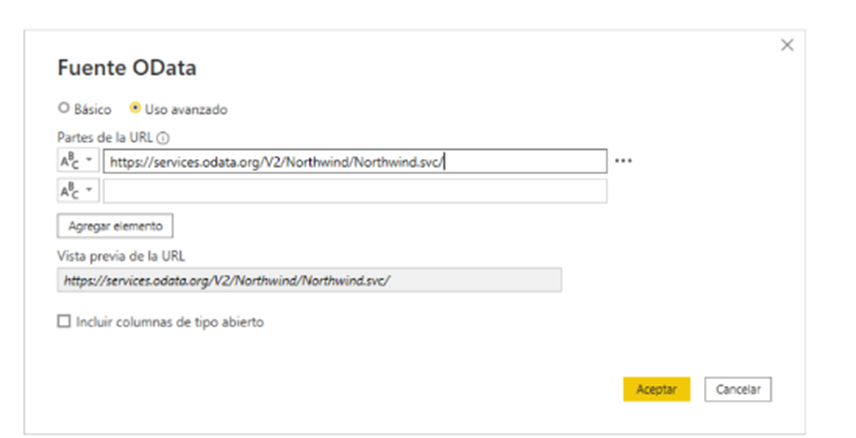
Para realizar una conexión OData en Power BI seleccionamos Obtener datos > Otras > Fuente OData.
Vamos a introducir el servicio de ejemplo Northwind como URL:
https://services.odata.org/V2/Northwind/Northwind.svc/
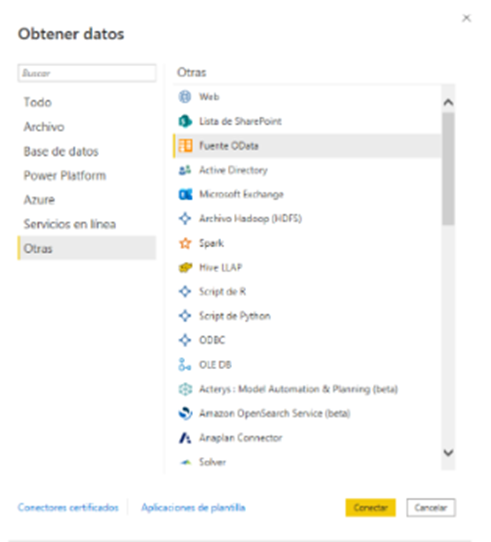
Introducimos la URL y seleccionamos autenticación anónima en el último nivel del servicio.
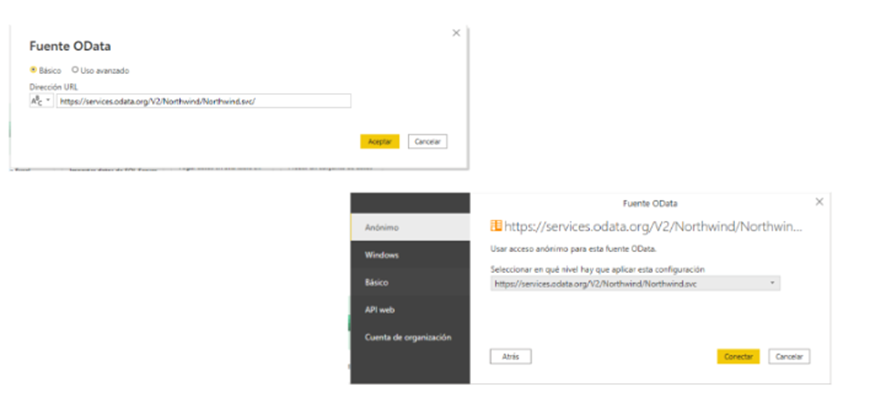
Nos aparece un desplegable con todos los recursos disponibles.
El conector de Power Query está construyendo por detrás las queries necesarias para acceder a ellos.
Podemos visualizar su contenido y cargar las tablas que nos interesen.
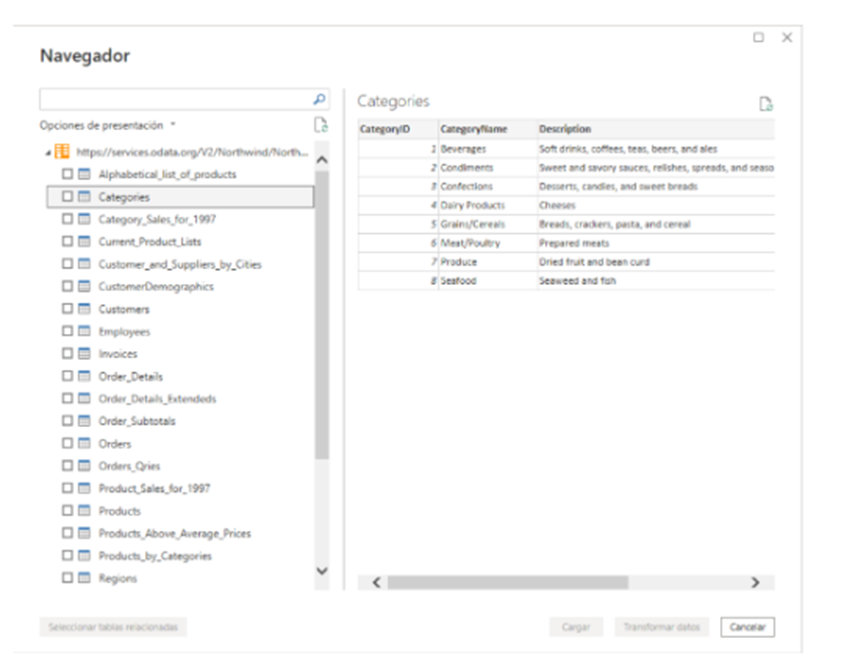
El conector permite también realizar personalizaciones de la query mediante su uso avanzado. Aquí podemos poner todas las opciones antes descritas.
Vamos a añadir un recurso y un filtro para ver cómo se construye la query.
Al cargar los datos vemos que efectivamente nos ha traído los primeros 5 productos.
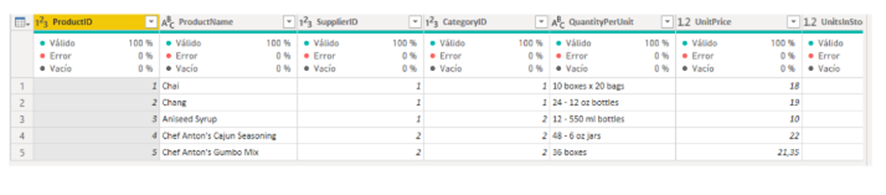
Personalizar la query ayudará a mantener el modelo de datos lo más simple posible.
Como se ha indicado antes, OData es un proyecto en continuo desarrollo que cuenta con varias versiones. En Power Query podemos ver que para esta API se está utilizando la implementación 2.0

Se puede seleccionar entre la implementación "2.0" o null para el resto de las versiones.